“Deep Research” for Scientific Literature Review
Introduction
Artificial intelligence (AI) is increasingly playing an integral role in helping researchers navigate the ever-expanding scientific literature. Innovations in natural language processing (NLP) and large language models (LLMs) promise to streamline how we discover, interpret, and compile research findings. Among the latest developments, Deep Research features from OpenAI and Google’s Gemini aim to autonomously gather online data, analyze and synthesize information, and return comprehensive summaries or research reports.
In this blog, I investigate whether these “Deep Research” tools can truly meet the rigorous standards of literature reviews demanded by scientific communities—particularly in a niche but rapidly growing area of generative models for inorganic crystal structures. I compare:
- OpenAI’s Deep Research built into ChatGPT Pro,
- Google Gemini’s Deep Research,
- A semi-manual approach, where I provide curated papers to the model.
Throughout this post, I’ll walk through the prompts used, the format of the generated reports, and how I evaluated factors such as information retrieval and research insight quality. Finally, I’ll present the highest-scoring merged report to show the best possible outcome from this mini-experiment.
What is “Deep Research”?
There is not a rigorous definition of “Deep Research”, but it generally refers to an AI-powered agent that autonomously conducts multi-step investigations by gathering, analyzing, and synthesizing diverse online data—from text and images to PDFs—to generate comprehensive, cited reports. This concept has origins in frameworks such as STORM and has been further developed by large players:
- OpenAI integrated a variant into ChatGPT for Pro subscribers.
- Google’s Gemini includes a “Deep Research” component for Gemini Advanced subscribers.
- Some open-source alternatives are also emerging.
Excitement has grown around these capabilities, fueled by user testimonials and demos. Researchers like me are wondering if these tools can expedite their literature reviews while maintaining rigor and reliability.
Deep Research for Scientific Studies
In academia, literature reviews are fundamental to scientific research. Scientists regularly summarize current research findings to identify trends, gaps, and future directions. If Deep Research could automate large portions of the review process, that would be a significant boon.
I chose generative models for inorganic crystal structures as my test case for several reasons. During my PhD research in computational materials design, I focused extensively on inorganic crystal materials and authored a review paper on crystal structure prediction (CSP). At that time, generative models were a relatively small subfield. However, there has since been an explosion of research in this area, with the emergence of new techniques like diffusion models, flow matching models, and foundation models, along with more application-oriented studies focusing on conditional generation. This topic is particularly relevant to me as I recently led a seed LDRD project on using crystal generative models for X-ray diffraction (XRD) structure determination. Given both my background and current research interests, I’m eager to understand how this field has evolved.
Simple Prompt Engineering for “Deep Research”
Rather than expecting a single, monolithic prompt to produce a full-blown review, I started by asking each system a guiding question:
I am a computational material scientist trying to do a literature review on generative models for inorganic crystal structure prediction/generation. What do you think I should pay attention to or focus on when reading through the papers?
This initial prompt helped the AI define an outline or review structure. Based on the responses, I then formulated a final prompt:
Can you help me research on generative models for inorganic crystal structure prediction/generation/design? Return me a report with three sections:
- A table with seven columns: authors/method, generative modeling approach, representation of crystal structures, data and training protocols, validation & evaluation metrics, interpretability, computational efficiency.
- A comparison of these methods and how the field has evolved.
- Discussion of gaps, challenges, and future directions.
OpenAI vs. Gemini vs. Semi-Manual
- OpenAI’s Deep Research
- After choosing “Deep Research,” ChatGPT typically asks follow-up questions to refine search criteria.
- An internal version of O3 model is used.
- It will output a rendered markdown file that the user can copy.
- I ran the same prompt (and minor clarifications) three times to see if results varied.
- I also merged the three outputs to see if it would improve the quality of the report.
- Google Gemini
- Gemini generates a research plan, requests user review, and then “executes” the plan.
- Currently only Gemini 1.5 Pro can be used for this feature.
- The final step yields a Google Doc-like report (which can be exported to other formats).
- I repeated the entire process three times as well.
- I also merged the three outputs to see if it would improve the quality of the report.
- Semi-Manual Approach
- I collected 27 relevant papers from my own personal research library (PDF format).
- Using Marker-PDF, I converted PDFs into markdown files. This will likely overcome paywalls and limited web-scraping issues.
- I fed these markdown documents as a context to LLM, prompting for the same final structure.
- I used Gemini 2 Pro for this approach due to context window constraints.
- I repeated the process three times as well.
- I also merged the three outputs to see if it would improve the quality of the report.
Finally, I also experimented with “merging” all individual reports from each approach to see if combining them could reduce errors or improve coverage. I ended up with 13 total reports (3 from each method, plus 4 merges). All the reports can be found in the Google Drive Folder
Gemini 2 Pro offers a generous 2-million token context window. My collection of 27 papers consumed only 10% of this capacity, suggesting that Gemini 2 Pro could theoretically handle over 200 full-length academic papers in a single context.
Evaluate Information Retrieval Effectiveness
First I want to see how effective each method is at retrieving the papers from the internet.

Observations:
- None of the methods can cover all references.
- Each deep research method has its own “preference” in terms of papers it retrieved.
- There are differences across repeated runs for deep research.
- The deep research methods indeed discover some references that the Semi-Manual approach missed.
- Merging outputs from different runs can improve coverage.
Overall, deep research methods can be convenient but can miss domain-specific or paywalled literature unless carefully prompted or otherwise augmented. A hybrid workflow (e.g., running multiple deep research attempts and also feeding in curated PDF/Markdown documents) may be the most robust for critical academic or R&D use cases.
Below is the full table of papers that were successfully retrieved across different attempts from Gemini, OpenAI, and the semi-manual method. Each row is a paper and each column is an attempt. The notation Y indicates that the method captured that reference. An empty slot indicates it was not cited or found in the final summary. By looking at the table in detail, we can see that each method has its own “preference” in terms of papers it retrieved. The Gemini method can retrieve very recent papers released in 2025 potentialy due to Google’s up to date search engine. The OpenAI method tends to retrieve more classic papers that are more related to generative models. The semi-manual method uses my own library of papers that are most relevant to the topic I care about such as XRD (i.e., conditional generation), which could be a bit niche and the reason why deep research methods miss those papers.
Use the navigation bar on the right to skip this very long table to the next section.
| Year | Author | Gemini_1 | Gemini_2 | Gemini_3 | OAI_1 | OAI_2 | OAI_3 | Manual |
|---|---|---|---|---|---|---|---|---|
| 2018 | Nouira et al. | Y | Y | Y | Y | |||
| 2019 | Noh et al. | Y | Y | Y | Y | Y | Y | |
| 2019 | Hoffmann et al. | Y | Y | |||||
| 2020 | Court et al. | Y | Y | Y | Y | Y | ||
| 2020 | Kim et al. | Y | Y | Y | Y | Y | ||
| 2020 | Kim et al. | Y | ||||||
| 2020 | Dan et al. | Y | ||||||
| 2020 | Pathak et al. | Y | ||||||
| 2021 | Xie et al. | Y | Y | Y | Y | |||
| 2021 | Long et al. | Y | Y | |||||
| 2021 | Zhao et al. | Y | ||||||
| 2022 | Ren et al. | Y | Y | |||||
| 2023 | Jiao et al. | Y | Y | Y | Y | |||
| 2023 | Zeni et al. | Y | Y | Y | ||||
| 2023 | Luo et al. | Y | Y | |||||
| 2023 | Chenebuah et al. | Y | ||||||
| 2023 | Yang et al. | Y | ||||||
| 2024 | Alverson et al. | Y | Y | |||||
| 2024 | Su et al. | Y | ||||||
| 2024 | Zhu et al. | Y | Y | |||||
| 2024 | Takahara et al. | Y | ||||||
| 2024 | Antunes et al. | Y | ||||||
| 2024 | Choudhary | Y | ||||||
| 2024 | Riesel et al. | Y | ||||||
| 2024 | Choudhary | Y | ||||||
| 2024 | Li et al. | Y | ||||||
| 2024 | Miller et al. | Y | Y | |||||
| 2024 | Gruver et al. | Y | ||||||
| 2024 | Lai et al. | Y | ||||||
| 2024 | Guo et al. | Y | ||||||
| 2024 | Pakornchote et al. | Y | ||||||
| 2024 | Mohanty et al. | Y | ||||||
| 2024 | Mishra et al. | Y | ||||||
| 2024 | Aykol et al. | Y | ||||||
| 2024 | Sriram et al. | Y | ||||||
| 2024 | Yang et al. | Y | ||||||
| 2024 | Lin et al. | Y | ||||||
| 2024 | Jiao et al. | Y | ||||||
| 2024 | Luo et al. | |||||||
| 2025 | Collins et al. | Y | Y | |||||
| 2025 | Luo et al. | Y | Y | Y | ||||
| 2025 | Kazeev et al. | Y | Y | |||||
| 2025 | Breuck et al. | Y | ||||||
| 2025 | Levy et al. | Y | Y | |||||
| 2025 | Tone et al. | Y | ||||||
| 2025 | Liu et al. | Y |
Evaluate Research Insights Quality
Next I wanted to see how effective each method is at generating insightful and novel research insights. I asked two different LLMs (OpenAI O1 Pro and Gemini 2 Pro) to act as a reviewer—scoring each report from 0 to 10 based on logical quality, understanding of papers, depth of thinking, and novelty of insights (rather than sheer length or grammatical quality). For each LLM reviewer, I ran the same prompt three times. Below is the prompt I used:
I have 13 reports on generative models for crystal structure and I need to grade them on a scale from 0 to 10, the focus is the quality of the content such as logic, paper understanding, thinking depth, idea novelty etc. We do NOT focus on quantity of the report such as number of papers cited, number of bullet points, length of report etc. We do NOT judge the grammar error, language usage or writing styles either. Can you come up with a good metric to reflect our focus on quality and grade those twelve reports and give your reasons for each. Return a table with report index, score, summary of reasons columns.
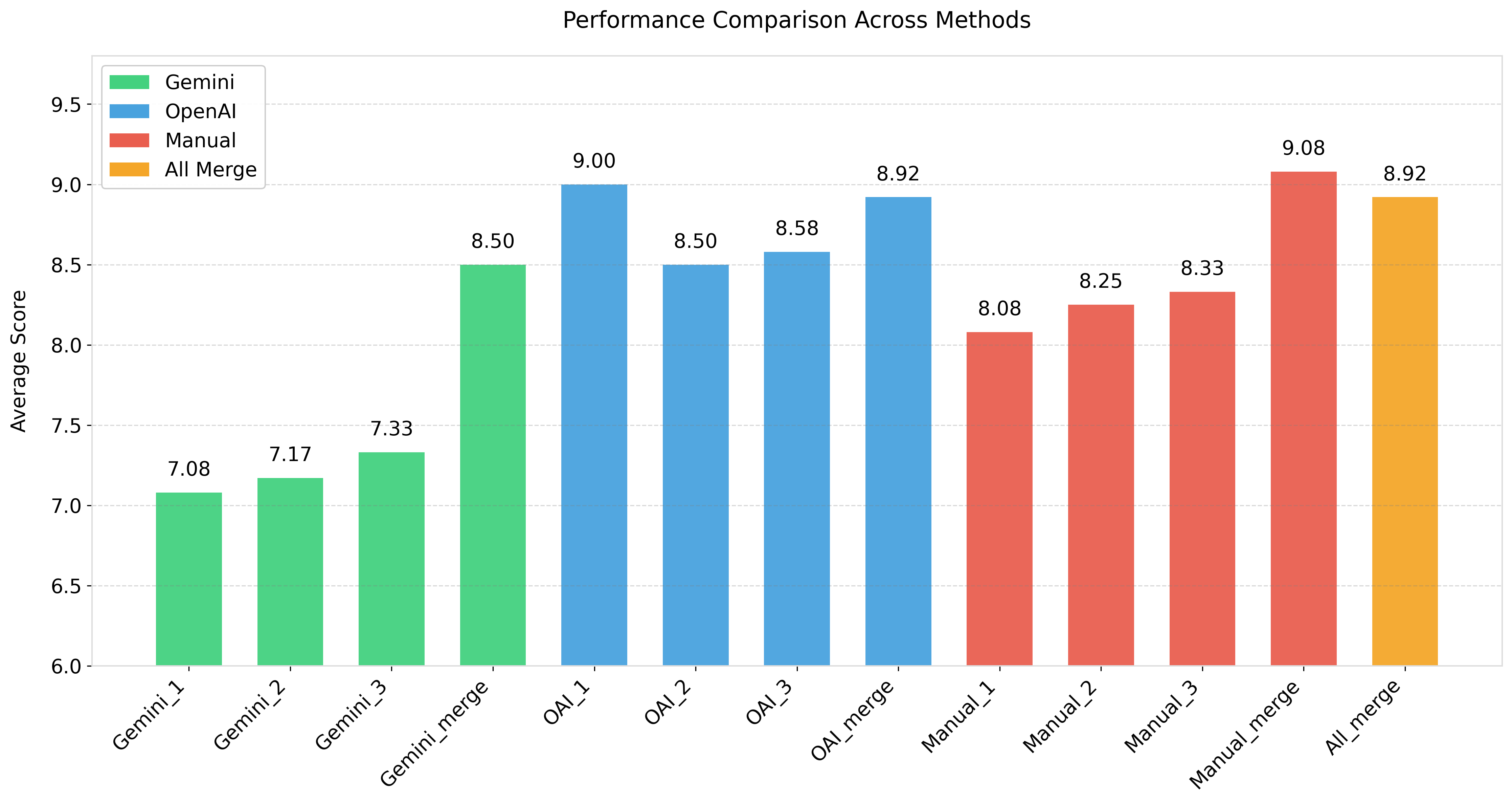
Observations:
- Most “merge” reports (e.g., Gemini_merge, OAI_merge, Manual_merge) achieve higher average scores than their individual runs. This suggests that combining multiple runs of the same method often leads to better synthesis and, consequently, a more robust final report.
- Manual_merge achieves the highest overall average (9.08). Interestingly, All_merge (which includes everything) does slightly worse at 8.92 overall—primarily because the Gemini reviewer gave it a comparatively lower score.
- One single-run report, OAI_1, has an overall average of 9.00, which is higher than both OAI_merge (8.92) and All_merge (8.92). This is an example of how sometimes a single “lucky” run can outperform a merge, depending on the content and the reviewer’s perspective.
- In some cases, the OpenAI (OAI) reviewer and the Gemini reviewer exhibit notable scoring differences. For example, Manual_1 receives 7.00 from OAI but 9.17 from Gemini. Conversely, All_merge receives 9.67 from OAI but only 8.17 from Gemini. These variations highlight that different reviewer models may emphasize different aspects of “quality.”
- While Gemini_merge does respectably at 8.50, the individual Gemini attempts (Gemini_1, Gemini_2, and Gemini_3) are at the lower end of the overall range (7.08–7.67). This could indicate that the Gemini-based reports benefited significantly from merging multiple attempts.
Below is the full table of the scores from both LLM reviewers:
| Report | OAI_score_1,2,3,avg | Gemini_score_1,2,3,avg | OAI_Gemini_avg |
|---|---|---|---|
| Gemini_1 | 8, 7, 7 (7.33) | 7.5, 7, 6 (6.83) | 7.08 |
| Gemini_2 | 7, 6, 7 (6.67) | 8, 8, 7 (7.67) | 7.17 |
| Gemini_3 | 8, 7, 8 (7.67) | 7, 7, 7 (7.00) | 7.33 |
| Gemini_merge | 9, 8, 8 (8.33) | 9, 9, 8 (8.67) | 8.50 |
| OAI_1 | 8, 9, 9 (8.67) | 9, 9, 10 (9.33) | 9.00 |
| OAI_2 | 8, 8, 8 (8.00) | 9, 9, 9 (9.00) | 8.50 |
| OAI_3 | 9, 9, 9 (9.00) | 8.5, 8, 8 (8.17) | 8.58 |
| OAI_merge | 10, 9, 9 (9.33) | 8.5, 9, 8 (8.50) | 8.92 |
| Manual_1 | 7, 7, 7 (7.00) | 8.5, 10, 9 (9.17) | 8.08 |
| Manual_2 | 8, 8, 8 (8.00) | 8.5, 9, 8 (8.50) | 8.25 |
| Manual_3 | 9, 8, 9 (8.67) | 8, 8, 8 (8.00) | 8.33 |
| Manual_merge | 9, 9, 9 (9.00) | 9.5, 9, 9 (9.17) | 9.08 |
| All_merge | 9, 10, 10 (9.67) | 8.5, 8, 8 (8.17) | 8.92 |
Conclusion
From this experiment, it’s clear that Deep Research tools can provide valuable and well-structured summaries, but they aren’t yet a drop-in replacement for a thorough, human-curated literature review—particularly in cutting-edge scientific fields.
Key Observations:
- Information retrieval is not yet up to par due to paywalls, limited web-scraping, and domain specificity.
- Merging multiple AI outputs can substantially improve final report quality
- The advanced models can generate interesting and novel research insights.
Overall, while the promise of “Deep Research” is highly appealing, scientists should remain actively involved for a thorough literature review. Nonetheless, the strides made in foundation models are both impressive and indicative of a rapidly evolving landscape. Deep research as for now is more like a starting point for a literature review. But it can be envisioned that future advancements in data sources, model capabilities, and workflow automation will make it a truly robust autonomous tool for literature review.
Highest Scored Final Report
Below is the final merged output from my semi-manual approach, which scored highest overall.
Section 1: Comprehensive Table of Methods
| Authors & Method (Year) | Generative Modeling Approach | Representation of Crystal Structures | Data & Training Protocols | Validation & Evaluation Metrics | Physical & Chemical Interpretability | Computational Efficiency & Practicality |
|---|---|---|---|---|---|---|
| Nouira et al., CrystalGAN (2019) | GAN (two cross-domain blocks with constraints) | 2D matrix (unit cell + fractional coordinates). | 1,416 binary hydrides (e.g., NiH, PdH) to generate ternary hydrides. Data augmentation used to diversify structures. | Number of generated ternary compositions satisfying geometric constraints (like interatomic distances). | Explicitly encodes geometric constraints (min/max atomic distances). | High throughput, though evaluation relies heavily on geometric rules rather than post-DFT stability checks. Focus is on a limited composition space (ternary hydrides). |
| Hoffmann et al. (2019) | VAE | 3D voxel grid (image-based). | Materials Project. | Structural validity, reconstruction accuracy; low success rates reported. | Lacks rotational invariance; voxel representations can be large and less chemically intuitive. | Voxel-based approach is computationally heavy and suffers from low validity rates. |
| Noh et al., iMatGen (2019) | VAE (hierarchical, two-step) | 3D voxel image (“cell image” + “basis image”), invertible to atomic positions & cell parameters. | 10,981 VxOy structures from MP (via elemental substitution). | RMSE of atomic positions & cell parameters; rediscovery of known VxOy structures; DFT validation for stability (energy above hull). | Demonstrates invertibility and reasonable stability predictions. Still uses voxel grids, which are memory-intensive. | More efficient than some genetic algorithms; requires post-processing for structure recovery; moderately high computational cost due to voxel approach. |
| Kim et al. (2020) | GAN | 3D point-based representation (atomic positions + lattice parameters). | Mg-Mn-O system from Materials Project. Data augmentation to reach ~112k structures. | DFT validation of newly generated structures (energy above convex hull). 23 new stable compounds identified. | Incorporates domain rules (compositions, stoichiometry). Targets stable crystals with Ehull < 0.2 eV/atom. | Less expensive than exhaustive searches; still requires DFT for final validation. |
| Ren et al., FTCP (2020) | Variational Autoencoder (VAE) + 1D CNN | Real-space (CIF-like: element matrix, lattice, site coords) + Reciprocal-space (Fourier transforms of crystal properties). | Materials Project; focuses on ternary crystals. Used for formation energy, bandgap, thermoelectric power factor design. | Validity rate, success rate (generated structures with target properties), improvement over random sampling. DFT used to confirm stability. | Explicitly considers both real-space and reciprocal-space info, improving periodic and electronic property representations. | Much faster than brute-force screening. DFT validation is still required for final check. |
| Xie et al., CDVAE (2021) | Diffusion model + VAE (“Crystal Diffusion VAE”) | Periodic multi-graph (atoms, bonds) with SE(3) equivariance adapted for crystals. | Perov-5, Carbon-24, MP-20 datasets. | Reconstruction, validity, diversity, property statistics (e.g., energy above hull). | Incorporates explicit periodic symmetry and an energy-based inductive bias. | Good performance across tasks but diffusion-based sampling can be relatively slow compared to simpler VAEs. |
| Pakornchote et al., DP-CDVAE (2023) | Diffusion probabilistic model + VAE | Fractional coordinates + lattice, building on CDVAE’s framework. | Perov-5, Carbon-24, MP-20. | Reconstruction accuracy, stability, ground-state performance (energy minimization). | Improves energy accuracy over standard CDVAE. | Similar complexity to other diffusion-based approaches; yields better ground-state structures. |
| Jiao et al., DiffCSP (2023) | Diffusion probabilistic model (E(3)-equivariant) | Fractional coordinates + lattice vectors, jointly diffused. | MP-20, Perov-5, Carbon-24. | Match rate, RMSE, stability checks, property statistics, space group distribution. | Captures periodic E(3) invariance; joint generation of lattice & coordinates yields better crystallographic symmetry. | Outperforms existing CSP models with moderate diffusion overhead. |
| Zeni et al., MatterGen (2023) | Diffusion probabilistic model | Atom types, coordinates, lattice (joint diffusion). | Alex-MP-20 (607,684 structures) as base training; fine-tuning on property-driven subsets. | Stability, uniqueness, novelty (S.U.N.) rate; RMSD vs. relaxed structures; property constraints. | Demonstrated ability to generate stable, novel materials. Fine-tuning for targeted properties. | High generation success rate; fine-tuning approach is flexible but adds training overhead. |
| Levy et al., SymmCD (2023) | Diffusion probabilistic model | Asymmetric unit & site symmetry, encoded as binary matrices. | MP-20. | Validity, diversity, space group distribution, RMSD, symmetry reproduction rate. | Innovative symmetry representation enables more consistent generation of non-trivial space groups. | Comparable diffusion approach with improved space group fidelity. |
| AI4Science et al., CrystalGFN (2023) | GFlowNet (Generative Flow Network) | Wyckoff positions + space group + composition constraints. | Datasets not fully specified; demonstration on select examples. | Symmetry analysis, structural validity, distribution over space groups. | Enforces symmetry constraints by design, generating structures consistent with a given space group. | GFlowNets can be efficient; method is relatively new in materials domain, so broader performance data limited. |
| Flam-Shepherd & Aspuru-Guzik (2023) | Language Model (trained from scratch) | CIF files treated as text. | MP-20. | Validity and structural metrics; comparisons to known structures from MP. | Text-based representation is flexible; direct generation of CIF strings. | Matches or outperforms some prior generative models but not explicitly symmetry-aware. |
| Jiao et al., DiffCSP++ (2023) | Diffusion model (enhanced from DiffCSP) | Fractional coordinates + lattice vectors (E(3)-equivariant). | MP-20, Perov-5, Carbon-24. | Match rate, RMSE, validity, property statistics. | Improves structural diversity and generation beyond unseen space groups compared to original DiffCSP. | Competitive performance and more efficient sampling than the original DiffCSP. |
| Gruver et al. (2024) | Large Language Model (fine-tuned LLM) | Text-encoded crystal data (“crystal strings” or CIF-like text). | Materials Project for structure data; extensive text corpora for pre-training. | Validity, coverage, property distribution, stability checks (DFT), diversity. | High stability rate; improved symmetry understanding through LLM’s language-based abstraction. | Computationally efficient sampling; flexible prompting for structure generation. |
| Antunes et al., CrystaLLM (2024) | Autoregressive Large Language Model | Complete CIF files as text tokens. | Millions of CIF files; large-scale pre-training. | Match rate (structure similarity), RMSE of positions, property-based conditioning tests. | Learns complex crystal-chemistry relationships; can condition on formation energy or space group. | High efficiency in generating valid CIFs; training is expensive but inference can be rapid. |
| Mishra et al., LLaMat (2024) | Pretrained LLM (LLaMA-based) + domain fine-tuning | Text + CIF data (materials literature, RedPajama, MP). | Large corpora (R2CID, 30B tokens), instruction fine-tuning on materials tasks, plus CIF files from MP. | F1 scores for textual tasks, match rate and RMSE for crystal generation, DFT stability checks. | Combines domain knowledge from literature with direct crystal structure data, enabling retrieval and generation. | Scales well to large text data. Efficient generation after fine-tuning. |
| Kazeev et al., Wyckoff Transformer (2024) | Transformer | Wyckoff positions as tokens (focus on space group & symmetry). | MP-20. | Novelty, uniqueness, symmetry distribution, property prediction accuracy. | Emphasizes crystal symmetry and site occupancy. Good generalization across common space groups. | Yields high novelty and structural diversity; handles up to moderate unit cell sizes. |
| Miller et al., FlowMM (2024) | Riemannian Flow Matching | Fractional coordinates + lattice parameters (atom types). | MP-20, Perov-5, Carbon-24. | Stability rate (energy above hull), S.U.N. rate, generation cost. | Rotation-invariant representation; advanced geometry handling. | Very fast inference, significantly more efficient than typical diffusion-based methods. |
| Choudhary, AtomGPT (2024) | Transformer (GPT-style) | Chemical & structural text descriptions. | JARVIS-DFT (formation energies, bandgaps, superconducting Tc). | MAE/RMSE for property prediction and structure generation tasks. | Targets forward (property) and inverse (structure) predictions. BCS superconductors highlighted. | Fine-tuning approach is relatively lightweight. Allows text-based property prompts. |
| Choudhary, DiffractGPT (2024) | Generative Pre-trained Transformer (GPT) | PXRD patterns to full crystal structure (text-based). | JARVIS-DFT; simulated and some experimental XRD data. | MAE, RMS deviation in predicted structure, match rate to known references. | Focuses on inverse design from PXRD. Potentially closes the loop with experimental characterization. | Easy integration with existing XRD analysis pipelines; inference is relatively fast. |
| Guo et al., PXRDNet (2024) | Diffusion Model | Lattice parameters + fractional coordinates from input PXRD patterns (nanomaterials). | MP-20-PXRD (simulated), plus experimental PXRD (IUCr database). | Rwp (weighted profile R-factor), material reconstruction success, breakdown by crystal system. | Good at handling nanoscale PXRD (peak broadening) and bridging the simulation-experiment gap. | Moderate computational cost with Langevin steps; outperforms older structure-solution techniques on complex nanomaterials. |
| Riesel et al. (2024) | Conditional Diffusion Model | Encoded PXRD patterns. | RRUFF, Materials Project, Powder Diffraction File (PDF) databases. | Match rate, cosine similarity to known PXRD peaks, visual comparison. | First large-scale demonstration for novel structure discovery from PXRD, including high-pressure phases. | Can determine unknown or unlabeled structures; computational cost is moderate for each reconstruction. |
| Q. Li et al., PXRDGen (2024) | Diffusion Model + Rietveld refinement | PXRD data, composition, fractional coordinates, lattice parameters. | MP-20. | Match rate, RMSE, R-factor after Rietveld refinement. | Addresses challenges like positioning light atoms and distinguishing near elements. | Automated structure determination from PXRD with high accuracy. |
| Cao et al., CrystalFormer (2024) | Transformer (autoregressive) | Wyckoff positions with assigned chemical elements. | MP-20. | Match rate, RMSE, novelty of generated structures. | Focuses on Wyckoff-based generation, improving symmetry handling. | Can generate many new templates exceeding prior diffusion/flow-based methods in certain space groups. |
| Zhu et al., WyCryst (2024) | VAE | Wyckoff positions + chemical elements (unordered sets). | MP-20. | Validity, match rate, space group distribution. | Captures symmetry within fixed space groups but has difficulty generalizing new symmetries. | Potentially fast training but less flexible across diverse space groups. |
| Aykol et al., a2c (Year not specified, ~2023-2024) | Deep learning potentials + subcell relaxation | Local structural motifs (subcells) of amorphous precursors (melt-quench MD). | Amorphous configurations from MD simulations, GNN potential used to predict crystallization. | Accuracy in predicting crystallization products vs. experimental observations (Ostwald’s rule). | Predicts final crystallized phase from amorphous states, bridging an important gap in materials synthesis. | High accuracy for diverse materials; specialized approach for amorphous → crystalline transformations. |
| Sriram et al., FlowLLM (2024) | Hybrid: Large Language Model + Flow Matching | Text-based prompts + learned flow transformations. | Not extensively detailed, but uses combined textual data (CIF) and structural knowledge for flow-based generation. | Standard generative metrics (validity, novelty) plus property consistency. | Combines LLM’s flexibility with geometry-aware flow methods. | Potentially efficient. Method is relatively new; broad performance data pending. |
| De Breuck et al., Matra-Genoa (Year not specified) | Autoregressive Transformer (“sequence to Wyckoff + coords”) | Sequenced Wyckoff representation + free coordinates and lattice parameters (hybrid discrete-continuous). | Materials Project and combined MP + “Alexandria” dataset. | Validity rates (bond lengths, space-group consistency), duplicate rates, S.U.N. ratio (Stable, Unique, Novel). DFT validation of some selected structures. | Explicitly uses symmetry tokens (Wyckoff), can condition on energy above hull or space group. | High throughput (up to 1000 structures/min). Uses robust relaxation workflow. |
Section 2: Comparison and Evolution of the Field
1. Early Attempts (pre-2020 to ~2020)
- Voxel / Image-Based Representations
- Early VAE approaches (e.g., Hoffmann et al., 2019; Noh et al., iMatGen, 2019) used 3D voxel grids or “image-like” unit-cell representations.
- Limitations: High memory usage, poor rotational invariance, and lower success rates in generating valid structures without extensive post-processing.
- Early VAE approaches (e.g., Hoffmann et al., 2019; Noh et al., iMatGen, 2019) used 3D voxel grids or “image-like” unit-cell representations.
- First GAN/Conditional Models
- Nouira et al., CrystalGAN (2019) and Kim et al. (2020) introduced GANs, often with constraints or data augmentation to respect atomic distances and stoichiometry.
- Focus: Generating limited composition spaces (e.g., hydrides or specific ternary systems) and demonstrating feasibility.
- Drawbacks: Typically had to rely on DFT checks after generation to confirm stability.
- Nouira et al., CrystalGAN (2019) and Kim et al. (2020) introduced GANs, often with constraints or data augmentation to respect atomic distances and stoichiometry.
2. Transition to Coordinate-Based and More Expressive Representations (2020–2021)
- Coordinate & Reciprocal-Space Features
- Ren et al., FTCP (2020) combined real-space (CIF-like) and reciprocal-space features, enabling both structure and property conditioning.
- Xie et al., CDVAE (2021) introduced diffusion-based generation within a VAE framework, leveraging graph neural networks with periodic boundary conditions.
- Ren et al., FTCP (2020) combined real-space (CIF-like) and reciprocal-space features, enabling both structure and property conditioning.
- Better Physical Inductive Bias
- Models started to embed crystal symmetry, minimal distances, or energy-based inductive biases (e.g., “score-based” or diffusion approaches).
- Result: Improved validity, diversity, and some gains in stability.
- Models started to embed crystal symmetry, minimal distances, or energy-based inductive biases (e.g., “score-based” or diffusion approaches).
3. Growth of Diffusion and Flow Methods (2021–2024)
- Diffusion Models
- DiffCSP, MatterGen, SymmCD, PXRDNet, DiffCSP++ employ diffusion-based techniques to incrementally refine random noise into plausible crystal structures.
- Advantages: Better sample quality, built-in symmetry or E(3)-equivariance, ability to condition on composition or PXRD data.
- DiffCSP, MatterGen, SymmCD, PXRDNet, DiffCSP++ employ diffusion-based techniques to incrementally refine random noise into plausible crystal structures.
- Flow-based Approaches
- Miller et al., FlowMM (2024) introduced Riemannian Flow Matching, improving efficiency over diffusion methods.
- GFlowNets (AI4Science et al., CrystalGFN) show promise for controlling generation paths in a more interpretable manner.
- Miller et al., FlowMM (2024) introduced Riemannian Flow Matching, improving efficiency over diffusion methods.
- Wyckoff-Driven / Symmetry-Centric Models
- Kazeev et al., Wyckoff Transformer (2024), Cao et al., CrystalFormer (2024), and Zhu et al., WyCryst (2024) incorporate Wyckoff positions, aiming for explicit space-group symmetry enforcement.
- SymmCD (2023) uses innovative binary matrix encoding of site symmetries.
- Kazeev et al., Wyckoff Transformer (2024), Cao et al., CrystalFormer (2024), and Zhu et al., WyCryst (2024) incorporate Wyckoff positions, aiming for explicit space-group symmetry enforcement.
4. Emergence of Large Language Models (LLMs) (2023–2024)
- Text-Based Generative Paradigm
- Gruver et al. (2024), Antunes et al., CrystaLLM (2024), Mishra et al., LLaMat (2024), and Flam-Shepherd & Aspuru-Guzik (2023) treat crystal data (CIF files) as text sequences.
- AtomGPT, DiffractGPT (2024) similarly adopt GPT-style architectures to handle forward/inverse design and PXRD-based inverse problem-solving.
- Gruver et al. (2024), Antunes et al., CrystaLLM (2024), Mishra et al., LLaMat (2024), and Flam-Shepherd & Aspuru-Guzik (2023) treat crystal data (CIF files) as text sequences.
- Benefits
- Easy to integrate domain knowledge (prompts), straightforward file-based input/output (CIF, XRD, text).
- Some solutions also incorporate property conditioning or space-group tokens, bridging purely numeric approaches with a flexible textual interface.
- Easy to integrate domain knowledge (prompts), straightforward file-based input/output (CIF, XRD, text).
5. Incorporation of Experimental Data
- PXRD-Conditioned Models
- Guo et al., PXRDNet (2024), Riesel et al. (2024), and Q. Li et al., PXRDGen (2024) directly tackle structure solution from powder X-ray diffraction (PXRD) patterns, bridging a gap between simulated training data and real-world experiments.
- Significance: Brings generative AI closer to experimental lab workflows, enabling near-instant predictions of unknown crystal structures from measured diffraction patterns.
- Guo et al., PXRDNet (2024), Riesel et al. (2024), and Q. Li et al., PXRDGen (2024) directly tackle structure solution from powder X-ray diffraction (PXRD) patterns, bridging a gap between simulated training data and real-world experiments.
Overall Evolution
- Representations: Moved from bulky voxel grids to coordinate-based, symmetry-aware, and text-based.
- Models: Evolved from early VAEs and GANs toward diffusion, flow, and hybrid LLM approaches.
- Scope: Expanded from small sets of elemental systems (binary/ternary) to large databases (MP-20, tens or hundreds of thousands of structures).
- Evaluation: Progressed from naive “validity only” checks to multi-criteria evaluations: stability (energy above hull), novelty, coverage of known crystals, symmetry fidelity, and direct property constraints.
Section 3: Gaps, Challenges, and Future Directions
1. Synthesizability Beyond Energy Above Hull
- Current Gap: DFT-based convex-hull calculations are used as a proxy for stability, but real-world synthesizability also depends on kinetics, metastability, defects, and reaction pathways.
- Challenge: Develop richer metrics (e.g., finite-temperature free energies, reaction pathways) or incorporate experimental feedback loops.
- Future Direction: Integration with robotic synthesis or active learning pipelines to iteratively validate and refine generative outputs based on actual experimental outcomes.
2. Multi-Property and Multi-Objective Optimization
- Current Gap: Most models can condition on a single property (e.g., bandgap) or incorporate stability constraints. Real applications often require balancing multiple properties (mechanical, optical, electronic).
- Challenge: Achieving robust multi-objective optimization in high-dimensional chemical spaces without sacrificing stability or validity.
- Future Direction: Reinforcement learning or classifier-free guidance within diffusion/flow frameworks, advanced reward mechanisms in GFlowNets, or hierarchical LLM prompts to handle conflicting property requirements.
3. Scaling to Complex & Large Systems
- Current Gap: Many benchmark datasets (MP-20, Perov-5, etc.) have relatively small unit cells. Complex structures (e.g., MOFs, zeolites, large supercells, interfaces) pose difficulties due to more extensive degrees of freedom.
- Challenge: Representations that can handle hundreds or thousands of atoms while maintaining invertibility and efficiency (e.g., hierarchical generation, segmenting the unit cell).
- Future Direction: Combining segment-based or hierarchical generative models, possibly guided by known building blocks (in MOFs or zeolites), or coarse-to-fine generation steps.
4. Data Limitations and Bias
- Current Gap: Public databases often contain predominantly stable, simpler structures, leading to biased training. Under-explored chemistries or meta-stable phases may be missing.
- Challenge: Enriching training data with negative examples, systematically sampling less-known chemical spaces, or leveraging active learning to expand coverage.
- Future Direction: Synthetic data generation that obeys fundamental chemical rules, or collaborative data-sharing from experimental labs focusing on “failed” or “inconclusive” syntheses.
5. Interpretability and Explainability
- Current Gap: Generative models, especially LLM-based or deep diffusion approaches, can be black boxes—difficult to probe for “why” certain structures are generated.
- Challenge: Materials scientists need interpretable insights to trust new predicted structures.
- Future Direction: Incorporate attention mechanisms or latent-space visualization to highlight chemical reasoning. Model distillation or rule-based post-processing that clarifies how constraints (symmetry, stoichiometry) are satisfied.
6. Integration with Experimental Data & Automation
- Current Gap: Most validation remains at the DFT level. Direct assimilation of partial or noisy experimental data (PXRD, electron microscopy, spectroscopy) is still developing.
- Challenge: Handling real experimental uncertainties, data heterogeneity, and bridging the “simulation-to-lab” gap.
- Future Direction: More robust, multimodal generative models that can fuse PXRD with other data sources (e.g., ED/EM images), plus closed-loop experimentation with robotic platforms.
7. Beyond Bulk Crystals: Surfaces, Defects, and Amorphous Materials
- Current Gap: Nearly all approaches target perfect periodic crystals. Real materials often have grain boundaries, defects, or are amorphous (e.g., a2c approach).
- Challenge: Extending generative methods to partial periodicity, surface reconstructions, heterostructures, or fully amorphous systems.
- Future Direction: Combining MD-based approaches (melt-quench) with generative networks that can propose stable or metastable configurations, or hierarchical representations for layered/defective structures.
Reuse
Citation
@online{yin2025,
author = {Yin, Xiangyu},
title = {“{Deep} {Research}” for {Scientific} {Literature} {Review}},
date = {2025-02-09},
url = {https://xiangyu-yin.com/content/post_deep_research.html},
langid = {en}
}